NexentaEdge Networking Considerations
NexentaEdge conceptually uses three types of networks:
- A backend Storage network: This is known as the Replicast network. It handles communications between the NexentaEdge servers.
- One or more Client Access networks: These enable conventional networking over standard networks.
- An optional Management network: This is a special customer-facing network which can be configured to limit management plane access to specifically enabled nodes.
The Client Access and optional Management network are managed by Linux using standard techniques. NexentaEdge software will favor specific techniques to limit the number of options that must be QA tested, but ultimately can support anything that Linux supports.
Gateway machines have access to the Replicast Netowrk, any Management network and one or more Cleint networks. By default each Gateway will be accessible by all Client Access Networks.
Target machines will only be accessible by the Replicast Network.
A typical topology:
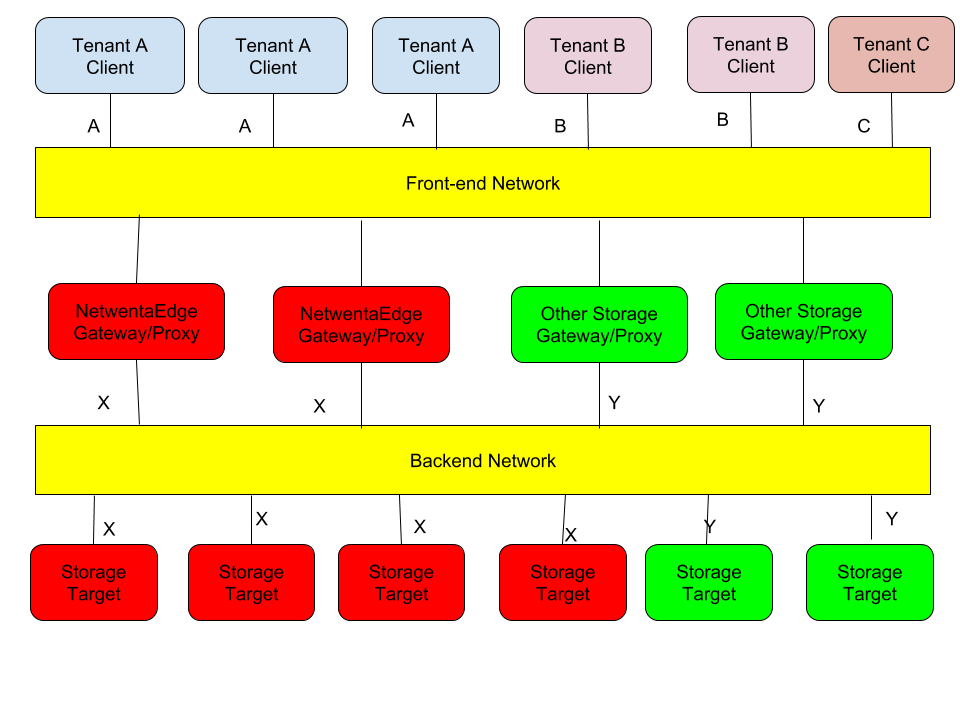
Network Configuration Using L2 networks
This section will outline what virtual L2 networks must be configured to support these three types. This document will focus on what is configured, not the specific methods of configuring L2 networks. But the required configurations should be obvious to any experienced network administrator.
The Client Access and optional Management networks are conventional L2 subnets. They must:
- Each subnet may be a VLAN or VXLAN tagged virtual network, or a switch enforced collection of ports. Traffic only travels between the subnets via routers.
- Both IPV4 and IPV6 subnets are supported, using pubic or private addresses.
- These networks are assumed to use standard congestion control algorithms with TCP Friendly Rate Control (TFRC).
- They do not have any special requirements for frame size or flow control support.
The preferred configuration for the Replicast network enables Replicast congestion control, which can greatly increase network utilization. For example, all payload transmissions will start at nearly wire speed. There is no required "warn up" of any connection. This is vital for scaling, because with a large cluster no given point-to-point connection will stay active. If there are 100 nodes then any given node would only be using 1 of 99 connections at a time.
The preferred configuration also uses IPv6 addressing, with all traffic using UDP for the transport layer. The IPV6 addresses are self-administered using Unique Local Addresses (RFC 4193). The network must support an MTU of at least 9000 bytes and either PAUSE or Priority Flow Control (PFC).
NexentaEdge can deal with almost any Replicast Network, however.
- To enable use of kernel bypass networking, a given Replicast network cannot mix frame formats. The choice of IP format and transport cannot vary. Ethernet frames must all be tagged or untagged.
- Congestion Control must be provided by standard TCP Friendly Rate Control protocols or be managed by the edge nodes on a closed subnet. The latter provides higher performance.
- The Replicast network must be closed. There can be no ingress or egress routes to non-Replicast subnets.
With the preferred solution the Replicast Network is extremely easy to configure. Just assign the switchports to a separate VLAN using untagged frames. The unicast addresses are self-assigned based upon the L2 MAC address. There is no need to assign addresses or to provision a DHCPv6 service. The default configuration will use UDP over IPv6 with Replicast Congestion Control.
The default congestion control does require pre-provisioning of a very large number of multicast addresses. Because the Replicast network is isolated from all other networks these addresses do not have to be co-ordinated with overall network configuration.
However, if the switches lack support for sufficient forwarding rules this will force the use of unicast messaging for payload transfers. This will take slightly more time for each payload transfer, but may be necessary when using switches without large forwarding tables.
Network Configuration With Kubernetes and other Orchestration Layers
Provisioning a NexentaEdge cluster with Kubernetes or other Orchestration Layers requires some special strategies unless the cluster is being deployed for a single tenant.
The three types of Networks described for NexentaEdge in the prior section are far from being a unique feature of NexentaEdge.
Support for multiple tenant networks is a common requirement to support smooth migration of legacy protocols designed when intranets were deployed on-premise in computer rooms.
While the use of an Orchestration Layer would hopefully eliminate the need for a Management Network it would not be uncommon for a storage cluster to require more configuration than the Orchestration Layer understood.
Specialized backend networks are also common, including:
- FibreChannel.
- InfiniBAnd.
- FCoE.
- NVMEoverFabric.
The bottom line is that NexentaEdge cannot be easily scheduled by the default Kubernetes scheduler. The same is probably true for many storage clusters. This can be worked around with special attributes, explicit enumeration of the machines to be selected or a custom scheduler.
Many storage clusters will require similar hardware, so the custom scheduler is a good solution. This will allow hardware intended to be storage servers to be dynamically assigned to a specific storage cluster.
Even if there are no hard requirements for specialized scheduling it will seldom make sense to allow generic scheduling to allocate hardware resources for storage clusters. Storage servers have different resource requirements for their balance of peristent storage resources versus networking resources versus compute resources. End customers like that their software defined storage solution can run on any hardware, but they prefer to run on a pre-approved reference design that the vendor has explicitly tested.
But there are two more fundamental issues with Orchestration Layer scheduling of storage clusters:
- Limiting as well as enabling storage cluster access. It is not enough to enable the required clients, all other clients must be excluded.
- The same storage cluster must be able to support multiple client access networks, which may be added or removed independently.
Rationale for Tenant-Specific Access networks
The Kubernetes default is for a flat network namespace, which requires each endpoint to decide for itself which connections to accept. They may or may not be aware of your endpoint, but there is nothing in the network to prevent any client from attempting to connect or use your service.
But there are options with Kubernetes, such as OpenVswitch, which allow selective network visibility. Many other orchestration layers make limited network access the default. For storage clusters deployed in a data-center these capabilities are vital for providing multi-tenant storage services. Tenant-specific networks provide security guarantees to tenants that are beyond what their own authentication service can provide. Their stored volumes/object/files cannot be accessed from nodes that are not admitted to their tenant specific client access network. Without access to the network an outsider cannot even try to guess passwords, nor can they observe what mount points are available or how much traffic is being exchanged.
When intranets were implemented in on-premise computer rooms this was enforced by perimeter firewalls. Potential storage service customers migrating from such an environment expect that there will be no reduction in their ability to keep their internal traffic completely invisible to the outside world.
But a storage cluster within a data center can achieve greater economies of scale if a single storage cluster can provide storage services to multiple tenants. But each of those tenants will demand that there be zero chance of information leaking to other tenants. Tenant-specific networks that are isolated by port assignment, vLANs or VXLANs achieve this in a way that is easily understood by end users because it operates the same way their network operated within their on-premise computer room.
A Gateway/Proxy localhost
Gateway/Proxy hosts are storage cluster machines which have access to both the frontend traffic carrying Client Access networks and the backend network carrying storage networks.
They are first scheduled as part of a storage cluster, which makes them eligible to add Tenant-specific Client Access Pods to provide service to a specific tenant.
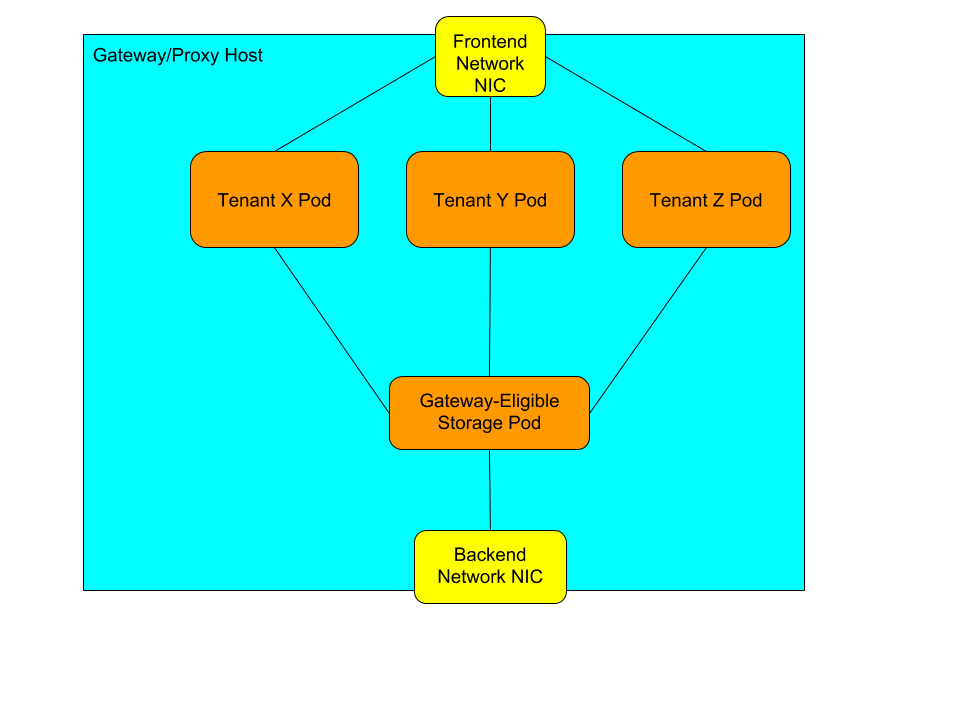
Storage Taeget hosts
Target-only hosts are even simpler.
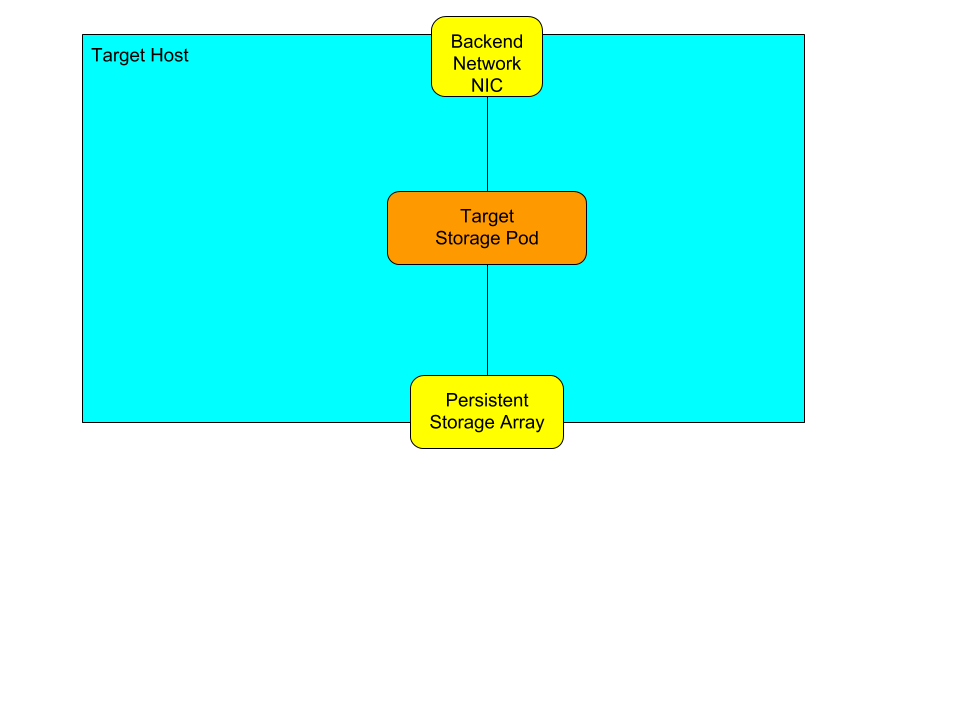
Dynamically Adding/Removing Client Access networks
A new Client Access network connects one or more Client containers with Components scheduled on machines already containing Gateway or Proxy containers attached to the Storage Network.
The Client containers can be scheduled anywhere. The new Gateway/Proxy containers must be scheduled on the Gateway/Proxy machines already selected for the Storage network. The newly added Gateway/Proxy containers will communicate with the Storage Server components using localhost IPC.
Ideally, an Orchestration Layer would just tell a multi-tenant Gateway/Proxy container to add a virtual interface to the Client Access network, but that capability is not yet supported.